My experience in Educational Codeforces Round 159
On Sunday, December 3, 2023, I participated in Educational Codeforces Round 159. This blog details my thought processes during and after the contest. Before reading this blog, I highly encourage you to try the problems for yourself.
For context, my rating going into this round was 1618, but my maximum rating of all time was 1774, attained nearly eight months prior. I had been on an unlucky streak of contests recently, with my rating constantly dropping for the past few months. (Or maybe I was just getting worse, but I refused to believe that.) With this contest, I hoped to at least gain some rating to try to offset my lost points.
1902A - Binary Imbalance
First, my mom comes into my room and asks me what I’m doing at 8:35 AM on a Sunday morning. Cool.
After that, I start reading the problem. It isn’t immediately obvious, but after reading the sample cases, I figure that the answer probably just depends on if the string has all ones.
I then realize that you can just spam zeroes where there are two unequal characters, and this will satisfy the condition. If there are no unequal characters, then the string must be a repeat of the same character. Then, if the string is all zeroes, then the condition is obviously satisfied already, and if it’s all ones, you can’t satisfy the condition.
I quickly code this logic in Python. I normally use C++ for competitive programming, but I use Python for the earlier problems because Python’s syntax is extremely concise, making implementation easy. And I have my first AC after two minutes!
1902B - Getting Points
Why is the problem statement so long and confusing… What are all these arbitrary conditions?
These are my thoughts when I first read the problem. So many variables, and the numbers 7 (days per week) and 2 (max tasks in a day) seem so weird and out of place.
I attempt to solve the problem, but I struggle with figuring out how many days to use: each day contributes $l+2t$, but at some point it just becomes $l+t$ or $l$ because you run out of tasks, and… The whole thing is utterly confusing to me.
Frustrated, I begin to wonder about a brute-force solution. I reason:
- After $1$ day, you can get $l+2t$ points.
- After $2$ days, you can get $2l+4t$ points.
- And so on, but after you’ve exhausted all the possible tasks, the coefficient of $t$ “maxes out.”
- The fact that the tasks unlock incrementally every week doesn’t matter, since you can just put all your days at the end.
Suddenly, the answer is obvious. Just binary search! I code this up in Python, and I have a second AC after 18 minutes.
1902C - Insert and Equalize
I read the problem statement, and I decide to first ignore the part about adding a new element. (This is always a good strategy in problem-solving—if the problem seems too complicated, figure out an easier version first.) Okay, so we have to make all the elements equal by repeatedly adding some chosen number $x$ to each element, and we want to minimize the number of additions.
…Wait, isn’t $x$ just the GCD?
I convince myself that $x$ is, in fact, just the GCD. (Specifically, the GCD of the differences with the maximum.) Then I figure that the added element should be $x$ more than the maximum—oh wait, the sample cases suggest that it can also be below the maximum. But just testing those two cases should work, right?
I make a few implementation errors, but finally manage to procure some Python code that passes samples. I submit this code, and 34 minutes into the contest, three problems are down.
1902D - Robot Queries
At this point, I start getting a little nervous. In almost all my past contests, I’d solved problems A through C, but problem D had consistently defeated me. This time, though, I’d sped through A through C and had almost an hour and a half to solve D.
I cast my emotions aside and start reading the problem. The first thing I do after reading is draw out the process for the first sample case. (I’m ignoring the reversing part for now.) I get this, with start labeled with red and end labeled with green:
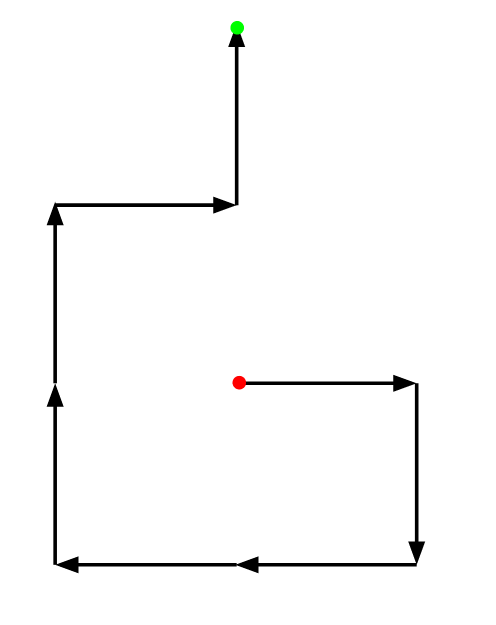
Then to figure out the effects of reversing, I reverse the whole sequence (RDLLUURU becomes URUULLDR) and draw the new process:
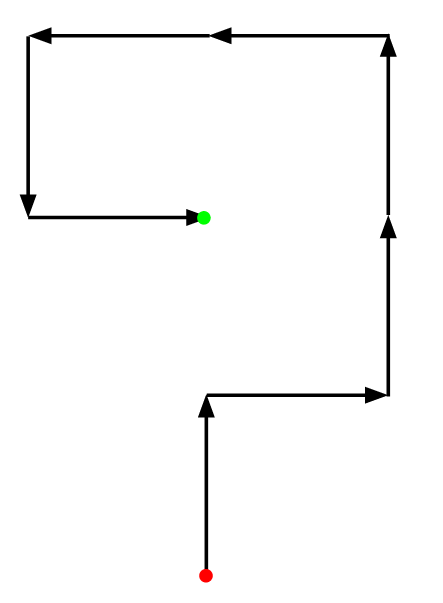
The new drawing looks similar to the previous, but I can’t formalize it. That is, until I start thinking about Rubik’s cubes (and group theory in general).
You see, if I wanted to undo the sequence R D L L U U R U on a cube, I would do U' R' U' U' L' L' D' R'. In other words, I would reverse the moves and also invert each move. So the process of just reversing the sequence of moves is like undoing the moves and inverting each move. Also note that in this problem, “undoing the moves” is analogous to traveling backwards, from the end point to the start point.
Now what does “inverting each move” look like in this problem? The inverse of left is right, and vice versa. Similarly, the inverse of down is up. But that’s just a 180 degree rotation!
So let’s say we have a “shape” for a string corresponding to the points visited in that string. The plan for calculating the “shape” for the reversed string is as follows:
- Let the starting point for the string be $S$ and the ending point be $E$.
- First, let’s translate the entire shape so that $E$ is at the origin.
- “Undoing the moves” means the shape stays the same—we’re just going the opposite way, which doesn’t change the relative location of the points visited.
- Now we “invert each move” by doing a 180 degree rotation, which is equivalent to multiplying each point by $-1$.
- Finally, we translate so that $E$ is on top of the original location of $S$. Intuitively, the reason we’re translating back to $S$ instead of $E$ is because when we “undid the moves,” we also swapped the start and end points.
We can encode this mathematically as well. Every point $A$ on the original shape corresponds to a point
\[A' = S + E - A\]on the new shape. Rearranging, we get that $A’$ is on the new shape if and only if
\[A = S + E - A'\]is on the original shape. (For clarification, we’re treating the points like vectors here, so “adding points” is like adding vectors.)
Around this point, I look at the solve counts, and I’m surprised to see that Problem E has more solves than Problem D, the one I’m currently working on. As I’m making good progress, though, I resolve to solve D first, then work on and maybe even solve E.
Looking back at the samples now, I realize that the queries are simple. If the point they ask for is $A$, I just need to check if $A$ is in the untransformed part or if $S+E-A$ is in the transformed part. By making a list of all the points that the robot touches, these queries reduce to “check if item in subarray,” and the last part of the puzzle is finding a way to answer these queries quickly.
I immediately recall an $O(\log^2 n)$ approach that I learned from Competitive Programmer’s Handbook, which involves setting up a segment tree of sets. I knew it was overkill, but at the very least, it would work, right?
I begin implementing. My implementation is riddled with errors; most notably, I realize I messed up my original calculations, incorrectly computing $A’=2E-A$ rather than $S+E-A$. But after many minutes of debugging, my code manages to pass samples.
1 hour and 37 minutes from the start of the contest, over an hour after I had started this problem, I submit my code. It gets a runtime error on test 13.
I start panicking a bit. Did I get trolled by D for the millionth time? I remind myself to stay calm, and seeing no other issue in my code, I reason that the “runtime error” is probably some sort of memory limit exceeded. I make a small optimization to the segment tree to use half the memory and submit again, four minutes later.
I wait in suspense for the submission to be judged. The text Running on test 14 appears on my screen, and I breathe a sigh of relief knowing that the bug had been fixed. Slowly, the test numbers increase as I wait for my Accepted verdict. Running on test 36, 37, 38…
…why is it spending so long on test 38?
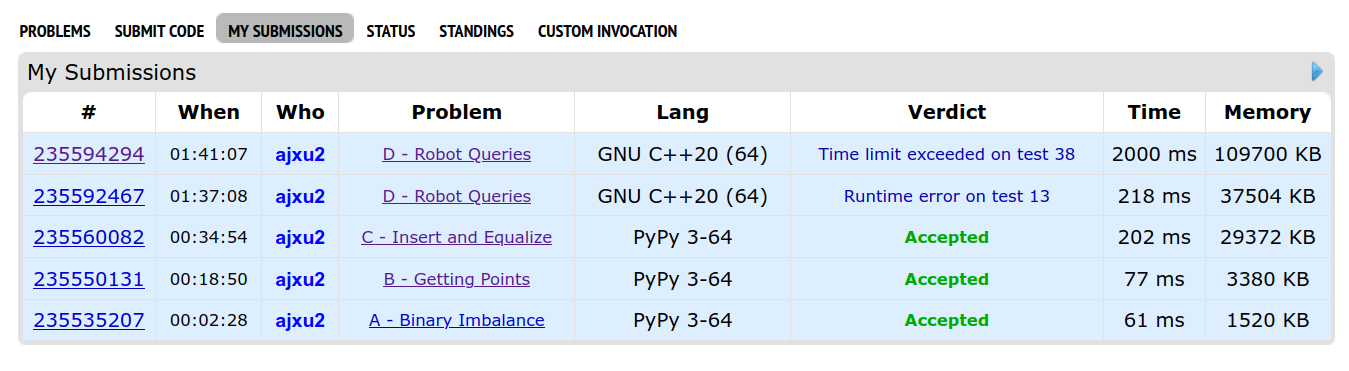
Yeah.
Once again, I had been defeated by Problem D and lost tens of potential rating points.
The remaining 19 minutes were spent trying to figure out what went wrong in my implementation and possible ways to optimize. I even tried implementing Mo’s algorithm for the first time out of desperation. In the end, though, no Accepted verdict came out of Problem D.
Post-contest
After discussing with other contestants, I realize I had exactly the right idea for D, but the segment tree idea was way too complicated. The correct idea was to just maintain a map storing the indices of every item. Oops. I guess that’s what happens when you study too much advanced stuff.
With this new idea, I re-implement the solution for problem D, and it easily gets an Accepted verdict. Code
A few hours later, I read problem E, and am able to solve it independently with string hashing. However, I don’t believe I would have solved it in contest, since I ran into issues with hash collision that would have been hard to find without seeing the test data. I won’t be going over my solution here, but it uses a similar approach as the editorial solution. The only difference is that I use hashing to calculate the LCP function, rather than a trie. Code
Reflection
I did end up gaining 23 rating points from this contest, but I was still unhappy with my performance. What could I have done better?
For starters, implementation speed was an issue. Had I implemented C and D faster, I might’ve had leftover time to find the correct approach for D. Implementation has been an issue for me forever, and it’s been the reason for many poor performances on contests. To remedy this, I could practice more moderate-level problems to build coding speed.
In this contest specifically, I had 19 minutes after my TLE verdict to figure out the issue. However, this time was not spent productively. I spent many of those minutes on implementing Mo’s algorithm, but if I had thought a bit more, I would have realized that Mo’s algorithm would TLE as well. Perhaps if I had delegated this time towards thinking of another approach, I could have found the correct solution. The lesson to learn from this is to not get too ahead of yourself, and to plan your attack wisely, so to speak.
I’ll also definitely continue practicing high rated problems ($\approx 2100$ rating) on Codeforces to expose myself to more concepts and ideas.
Anyway, that’s all I have. Goodbye, and I hope your future Codeforces contests go better than this one did! ;)